




文章目录
MySQL 执行一条查询语句的内部执行过程?
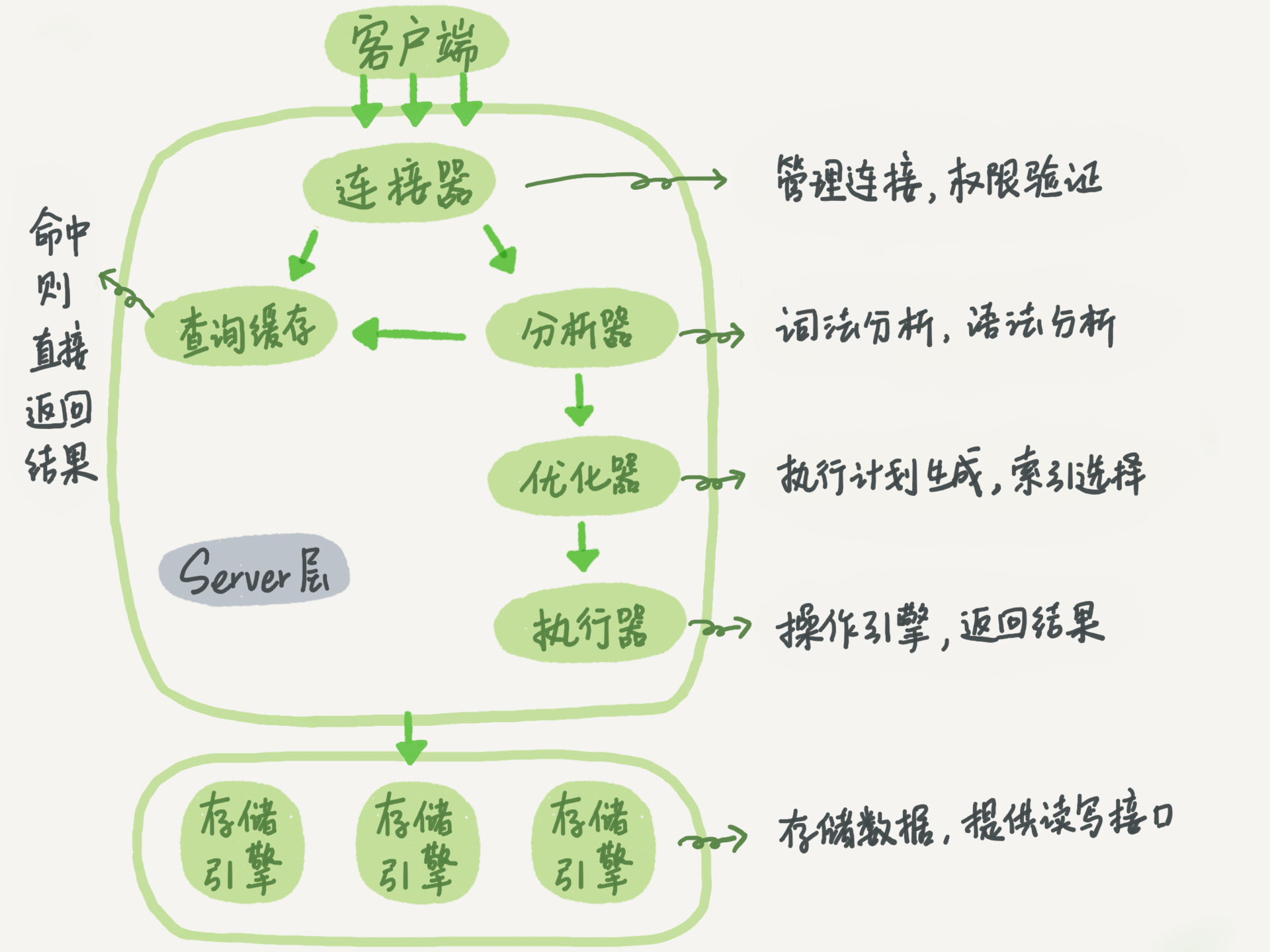
客户端先通过连接器连接到 MySQL 服务器。
连接器权限验证通过之后,先查询是否有查询缓存,如果有缓存(之前执行过此语句)则直接返回缓存数据,如果没有缓存则进入分析器。
分析器会对查询语句进行语法分析和词法分析,判断 SQL 语法是否正确,如果查询语法错误会直接返回给客户端错误信息,如果语法正确则进入优化器。
优化器是对查询语句进行优化处理,例如一个表里面有多个索引,优化器会判别哪个索引性能更好。
优化器执行完就进入执行器,执行器就开始执行语句进行查询比对了,直到查询到满足条件的所有数据,然后进行返回。
MySQL通信协议
程序或者工具要操作数据库,第一步要做什么事情?跟数据库建立连接,这里就涉及到客户端和MySQL服务端之间的通信协议。
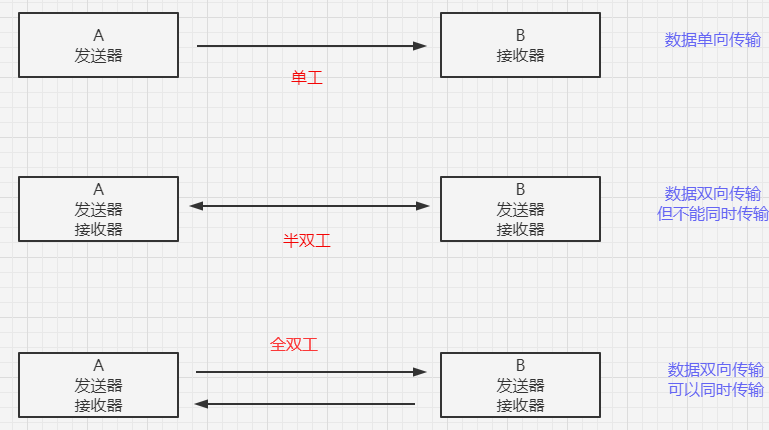
MySQL客户端/服务端通信协议是“半双工”的:在任一时刻,要么是服务器向客户端发送数据,要么是客户端向服务器发送数据,这两个动作不能同时发生。一旦一端开始发送消息,另一端要接收完整个消息才能响应它,所以我们无法也无须将一个消息切成小块独立发送,也没有办法进行流量控制。
客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置max_allowed_packet(默认是 4M)参数。但是需要注意的是,如果查询实在是太大,服务端会拒绝接收更多数据并抛出异常。
与之相反的是,服务器响应给用户的数据通常会很多,由多个数据包组成。但是当服务器响应客户端请求时,客户端必须完整的接收整个返回结果,而不能简单的只取前面几条结果,然后让服务器停止发送。因而在实际开发中,尽量保持查询简单且只返回必需的数据,减小通信间数据包的大小和数量是一个非常好的习惯,这也是查询中尽量避免使用SELECT *以及加上LIMIT限制的原因之一。
详细的协议分析请参考: 数据库–MySQL服务器和客户端通信协议
Unix Socket
我们在 Linux 服务器上,如果没有指定-h 参数,它就用 socket 方式登录(省略了-S /var/lib/mysql/mysql.sock)。它不用通过网络协议,也可以连接到 MySQL 的服务器,它需要用到服务器上的一个物理文件(/var/lib/mysql/mysql.sock)
select @@socket; -- /var/lib/mysql/mysql.sock
TCP/IP 协议
mysql -h192.168.1.6 -uroot -p123456
如果指定-h 参数,就会用第二种方式,TCP/IP 协议
我们的编程语言的连接模块都是用 TCP 协议连接到 MySQL 服务器的,比如 mysql-connector-java-x.x.xx.jar
另外还有命名管道(Named Pipes)和内存共享(Share Memory)的方式,这两种通信方式只能在 Windows 上面使用,一般用得比较少
通信方式
连接方式
MySQL 是支持多种通信协议的,可以使用同步/异步的方式,支持长连接/短连接。
一般来说我们连接数据库都是同步连接。连接方式: 长连接或者短连接
MySQL 既支持短连接,也支持长连接。短连接就是操作完毕以后,马上 close 掉。长连接可以保持打开,减少服务端创建和释放连接的消耗,后面的程序访问的时候还可以使用这个连接
一般我们会在连接池中使用长连接。保持长连接会消耗内存。长时间不活动的连接,MySQL 服务器会断开
MySQL交互时间
默认都是 28800 秒,8 小时
mysql> show global variables like 'wait_timeout'; -- 非交互式超时时间,如 JDBC 程序 +---------------+-------+ | Variable_name | Value | +---------------+-------+ | wait_timeout | 28800 | +---------------+-------+ 1 row in set (0.08 sec) -> show global variables like 'interactive_timeout'; -- 交互式超时时间,如数据库工具 +---------------------+-------+ | Variable_name | Value | +---------------------+-------+ | interactive_timeout | 28800 | +---------------------+-------+ 1 row in set (0.08 sec)
查看 MySQL 当前有多少个连接?
show global status like 'Thread%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_cached | 5 | | Threads_connected | 52 | | Threads_created | 617 | | Threads_running | 1 | +-------------------+-------+ 4 rows in set (0.18 sec)
Threads_cached:缓存中的线程连接数
Threads_connected:当前打开的连接数
Threads_created:为处理连接创建的线程数
Threads_running:非睡眠状态的连接数,通常指并发连接数。
每产生一个连接或者一个会话,在服务端就会创建一个线程来处理。反过来,如果要杀死会话,就是 Kill 线程。
一些常见的状态:https://dev.mysql.com/doc/refman/5.7/en/thread-commands.html
mysql> SHOW PROCESSLIST; +--------+-------+---------------------+-------+---------+------+----------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +--------+-------+---------------------+-------+---------+------+----------+------------------+ | 167162 | xwder | 172.17.0.1:36108 | xwder | Query | 0 | starting | SHOW PROCESSLIST | +--------+-------+---------------------+-------+---------+------+----------+------------------+
| 状态 | 含义 |
|---|---|
| Sleep | 线程正在等待客户端,以向它发送一个新语句 |
| Query | 线程正在执行查询或往客户端发送数据 |
| Locked | 该查询被其它查询锁定 |
| Copying to tmp table on disk | 临时结果集合大于 tmp_table_size。线程把临时表从存储器内部格式改变为磁盘模式,以节约存储器 |
| Sending data | 线程正在为 SELECT 语句处理行,同时正在向客户端发送数据 |
| Sorting for group | 线程正在进行分类,以满足 GROUP BY 要求 |
| Sorting for order | 线程正在进行分类,以满足 ORDER BY 要求 |
查看最大连接数
mysql> show variables like 'max_connections'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 200 | +-----------------+-------+ 1 row in set (0.07 sec)
show 的参数说明:
1、级别:会话 session 级别(默认);全局 global 级别
2、动态修改:set (set global max_connections = 1000;),重启后失效;永久生效,修改配置文件/etc/my.cnf
查询缓存
MySQL 的缓存默认是关闭的,在 MySQL 8.0 中,查询缓存已经被移除了。
默认关闭的意思就是不推荐使用,为什么 MySQL 不推荐使用它自带的缓存呢?
主要是因为 MySQL 自带的缓存的应用场景有限
第一个是它要求 SQL 语句必须一模一样,中间多一个空格,字母大小写不同都被认为是不同的的 SQL
第二个是表里面任何一条数据发生变化的时候,这张表所有缓存都会失效,所以对于有大量数据更新的应用,也不适合
所以缓存这一块,我们还是交给 ORM 框架(比如 MyBatis 默认开启了一级缓存),或者独立的缓存服务,比如 Redis 来处理更合适
在解析一个查询语句前,如果查询缓存是打开的,那么MySQL会检查这个查询语句是否命中查询缓存中的数据。如果当前查询恰好命中查询缓存,在检查一次用户权限后直接返回缓存中的结果。这种情况下,查询不会被解析,也不会生成执行计划,更不会执行。
MySQL将缓存存放在一个引用表(不要理解成table,可以认为是类似于HashMap的数据结构),通过一个哈希值索引,这个哈希值通过查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。
如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、mysql库中的系统表,其查询结果都不会被缓存。比如函数NOW()或者CURRENT_DATE()会因为不同的查询时间,返回不同的查询结果,再比如包含CURRENT_USER或者CONNECION_ID()的查询语句会因为不同的用户而返回不同的结果,将这样的查询结果缓存起来没有任何的意义。
语法解析和预处理 (Parser & Preprocessor)
这个就是 MySQL 的 Parser 解析器和 Preprocessor 预处理模块。
这一步主要做的事情是对语句基于 SQL 语法进行词法和语法分析和语义的解析
词法解析
词法分析就是把一个完整的 SQL 语句打碎成一个个的单词
比如一个简单的 SQL 语句:
select name from user where id = 1;
它会打碎成 8 个符号,每个符号是什么类型,从哪里开始到哪里结束
语法解析
语法分析会对 SQL 做一些语法检查,比如单引号有没有闭合,然后根据 MySQL 定义的语法规则,根据 SQL 语句生成一个数据结构。这个数据结构我们把它叫做解析树(select_lex)。
预处理器
如果我写了一个词法和语法都正确的 SQL,但是表名或者字段不存在,会在哪里报错?是在数据库的执行层还是解析器? 比如:select * from abc;
解析器可以分析语法,但是它怎么知道数据库里面有什么表,表里面有什么字段呢?实际上还是在解析的时候报错,解析 SQL 的环节里面有个预处理器。它会检查生成的解析树,解决解析器无法解析的语义。比如,它会检查表和列名是否存在,检查名字和别名,保证没有歧义。预处理之后得到一个新的解析树
查询优化(Query Optimizer)与查询执行计划
优化器
得到解析树之后,是不是执行 SQL 语句了呢?一条 SQL 语句是不是只有一种执行方式?或者说数据库最终执行的 SQL 是不是就是我们发送的 SQL?
这个答案是否定的。一条 SQL 语句是可以有很多种执行方式的,最终返回相同的结果,他们是等价的
但是如果有这么多种执行方式,这些执行方式怎么得到的?最终选择哪一种去执行?根据什么判断标准去选择?
这个就是 MySQL 的查询优化器的模块(Optimizer)
查询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选择一种最优的执行计划,MySQL 里面使用的是基于开销(cost)的优化器,那种执行计划开销最小,就用哪种
https://dev.mysql.com/doc/refman/5.7/en/server-status-variables.html#statvar_Last_query_cost
可以使用这个命令查看查询的开销:
show status like ‘Last_query_cost’;
优化器可以做什么
MySQL 的优化器能处理哪些优化类型呢?
1、当我们对多张表进行关联查询的时候,以哪个表的数据作为基准表
2、有多个索引可以使用的时候,选择哪个索引
实际上,对于每一种数据库来说,优化器的模块都是必不可少的,他们通过复杂的算法实现尽可能优化查询效率的目标,但是优化器也不是万能的,并不是再垃圾的 SQL 语句都能自动优化,也不是每次都能选择到最优的执行计划,大家在编写 SQL 语句的时候还是要注意
优化器是怎么得到执行计划的?
https://dev.mysql.com/doc/internals/en/optimizer-tracing.html
首先我们要启用优化器的追踪(默认是关闭的):
SHOW VARIABLES LIKE 'optimizer_trace'; set optimizer_trace='enabled=on';
注意开启这开关是会消耗性能的,因为它要把优化分析的结果写到表里面,所以不要轻易开启,或者查看完之后关闭它(改成 off)
注意:参数分为 session 和 global 级别
接着我们执行一个 SQL 语句,优化器会生成执行计划:
select t.tcid from teacher t,teacher_contact tc where t.tcid = tc.tcid;
这个时候优化器分析的过程已经记录到系统表里面了,我们可以查询:
select * from information_schema.optimizer_trace\G
它是一个 JSON 类型的数据,主要分成三部分,准备阶段、优化阶段和执行阶段
join_preparation-SQL准备阶段
join_optimization-SQL优化阶段
join_execution-SQL执行阶段
分析完记得关掉它
set optimizer_trace=”enabled=off”;
SHOW VARIABLES LIKE ‘optimizer_trace’;
优化器得到的结果
优化器最终会把解析树变成一个查询执行计划,查询执行计划是一个数据结构。当然,这个执行计划是不是一定是最优的执行计划呢?不一定,因为 MySQL 也有可能覆盖不到所有的执行计划。
怎么查看 MySQL 的执行计划呢?比如多张表关联查询,先查询哪张表?在执行查询的时候可能用到哪些索引,实际上用到了什么索引?
MySQL 提供了一个执行计划的工具。我们在 SQL 语句前面加上 EXPLAIN,就可以看到执行计划的信息
EXPLAIN select name from user where id=1;
注意: Explain 的结果也不一定最终执行的方式
存储引擎
我们创建的每一张表都可以指定它的存储引擎,而不是一个数据库只能使用一个存储引擎。存储引擎的使用是以表为单位的。而且,创建表之后还可以修改存储引擎,一张表使用的存储引擎决定我们存储数据的结构。
我们先要找到数据库存放数据的路径:
默认情况下,每个数据库有一个自己文件夹,以 xwder数据库为例,任何一个存储引擎都有一个 frm 文件,这个是表结构定义文件
mysql> show variables like 'datadir'; +---------------+-----------------+ | Variable_name | Value | +---------------+-----------------+ | datadir | /var/lib/mysql/ | +---------------+-----------------+ 1 row in set (0.16 sec)
不同的存储引擎存放数据的方式不一样,产生的文件也不一样,innodb 是 1 个,memory 没有,myisam 是两个。
常用的存储引擎 InnoDB 和 MyISAM 有什么区别?
InnoDB 和 MyISAM 最大的区别是 InnoDB 支持事务,而 MyISAM 不支持事务,它们主要区别如下:
InnoDB 支持崩溃后安全恢复,MyISAM 不支持崩溃后安全恢复;
InnoDB 支持行级锁,MyISAM 不支持行级锁,只支持到表锁;
InnoDB 支持外键,MyISAM 不支持外键;
MyISAM 性能比 InnoDB 高;
MyISAM 支持 FULLTEXT 类型的全文索引,InnoDB 不支持 FULLTEXT 类型的全文索引,但是 InnoDB 可以使用 sphinx 插件支持全文索引,并且效果更好;
InnoDB 主键查询性能高于 MyISAM。
如何选择存储引擎
如果对数据一致性要求比较高,需要事务支持,可以选择 InnoDB
如果数据查询多更新少,对查询性能要求比较高,可以选择 MyISAM
如果需要一个用于查询的临时表,可以选择 Memory
如果所有的存储引擎都不能满足你的需求,并且技术能力足够,可以根据官网内部手册用 C 语言开发一个存储引擎:https://dev.mysql.com/doc/internals/en/custom-engine.html
执行引擎(Query Execution Engine),返回结果
存储引擎,它是我们存储数据的形式,是谁使用执行计划去操作存储引擎呢?
这就是我们的执行引擎,它利用存储引擎提供的相应的 API 来完成操作
为什么我们修改了表的存储引擎,操作方式不需要做任何改变?
因为不同功能的存储引擎实现的 API 是相同的。最后把数据返回给客户端,即使没有结果也要返回
整理自:MySQL查询SQL执行流程